Autonomous vehicles (AVs) hold the promise of revolutionizing transportation, yet developing robust decision-making systems for complex urban navigation remains a significant challenge. This project addresses this by developing and evaluating a reinforcement learning (RL) framework for autonomous driving within the CARLA simulator. A Double Deep Q-Network (DDQN) agent, integrating a Convolutional Neural Network (CNN) for spatial feature extraction from camera imagery and a Long Short-Term Memory (LSTM) network for temporal understanding, was implemented from scratch. The agent was trained to select from six discrete driving actions. Initial training attempts relying on pure exploration proved insufficient. Consequently, a modified strategy incorporating CARLA's built-in autopilot as a guiding baseline was adopted, alongside a custom reward function encouraging both safety and driving speed. After 40,000 training frames, the final model demonstrated a significant improvement in driving performance compared to its untrained state and the baseline autopilot. The agent successfully navigated simulated urban environments, both with and without traffic, exhibiting smooth control, collision avoidance, and lane adherence. This work validates the efficacy of the CNN+LSTM DDQN approach for autonomous driving tasks in simulation and highlights the importance of guided learning strategies. The developed system provides a foundational step towards more sophisticated autonomous decision-making.
Introduction
With the rapid development of technology, autonomous vehicles provide a potential way to revolutionize transportation by improving safety, reducing traffic congestion, and enhancing mobility. However, developing autonomous vehicles (AVs) capable of safely and efficiently navigating complex urban environments is a significant challenge in both artificial intelligence and robotics fields. Traditional rule-based systems struggle to handle the vast variability and unpredictability inherent in real-world driving scenarios. Hence, reinforcement learning seems to be a possible solution to autonomous driving and is gaining popularity in the Robotics field. The primary problem addressed in this project is to develop a robust decision-making framework for autonomous vehicles using reinforcement learning (RL). Since real-world data is not easy to obtain, the whole system would be implemented in the CARLA simulator, a realistic open-source simulator for developing autonomous vehicles.
Approaches
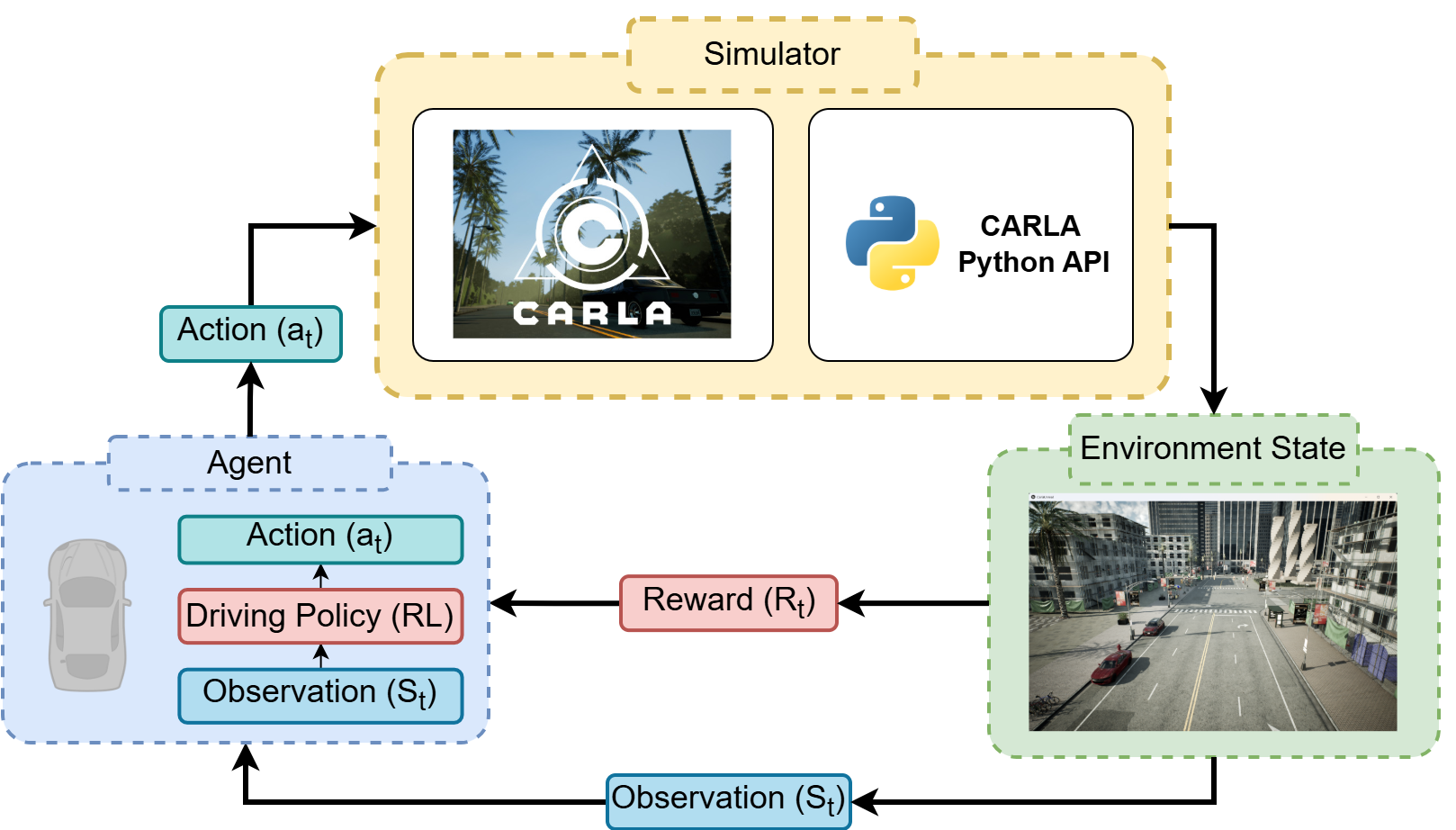
The project consists of three main components: a simulator, the environment state, and an
agent.
The simulator generates environmental data. The environment state provides input for the
model, including observations and rewards. The agent is the reinforcement
learning model that is trained. By taking observations, it generates actions which
are control commands sent back to the car in the simulator.
> 1. CARLA Simulator
CARLA is an open-source simulator for autonomous driving research that provides a powerful
Python API to control simulation aspects like traffic, pedestrians, weather, and sensors. It
allows configuration of diverse sensors such as LIDARs, cameras, depth sensors, and GPS. In
this project, CARLA was used to generate environmental datasets and provide camera frame
observations for the agent. An RGB-camera with 640 x 480 resolution and a 110-degree FOV was
used, along with a collision sensor. To simulate traffic, 15 non-player characters (NPCs)
were spawned. For each epoch, the environment was reset, and the car was spawned in a random
position to enable learning in diverse situations. The agent could choose from six discrete
actions: hard left-turn, soft left-turn, straight, soft right-turn, hard right-turn, and
emergency stop.
> 2. Driving Policy (Reinforcement Learning, RL)
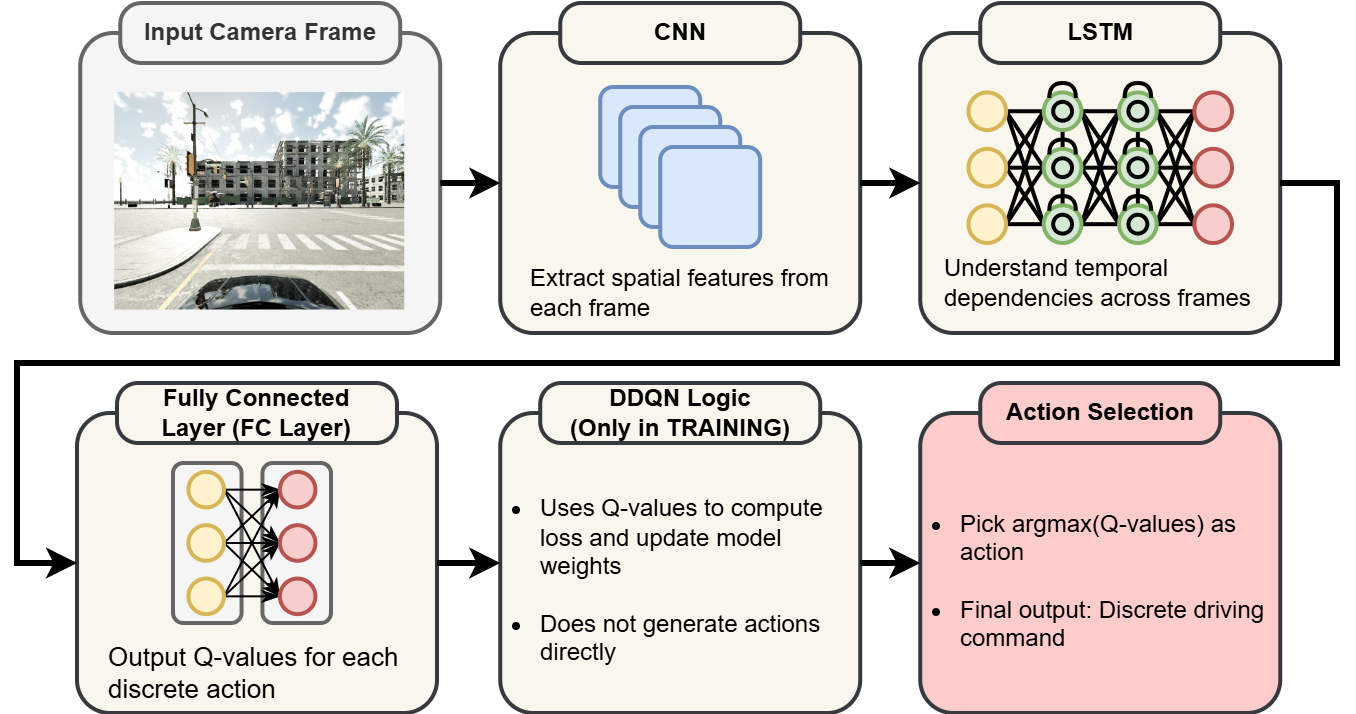
The project's goal was to develop a DDQN model so a car can cruise autonomously without
collisions. A study by Khlifi et al. (2025) suggested a CNN+LSTM-based DDQN agent is a
good approach. The workflow starts with capturing and preprocessing image frames from a
front-facing camera. A CNN extracts spatial features (e.g., road structure, obstacles),
which are then fed into an LSTM to capture temporal dependencies, enabling the agent to
understand motion and context. The LSTM's output goes through fully connected layers to
generate Q-values for each possible driving action. During training, DDQN logic, using a
target network alongside the online network, updates the CNN, LSTM, and fully connected
layers based on observed rewards to minimize overestimation bias. The final action is
selected by picking the one with the highest Q-value.
A modified reward function was used to encourage both safety and speed. The function is
expressed as:
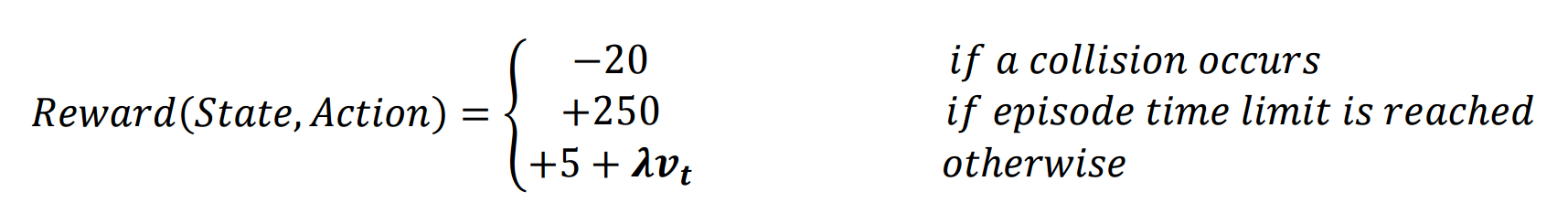
Where Vt is the vehicle's speed and λ is a positive weight, set to 0.2 in
this project.
> 3. DDQN Agent Implementation
The DDQN agent was implemented with the following key settings:
The DriverModel consists of a three-layer CNN for feature extraction, an LSTM network with a hidden size of 256 to process the sequential features, and a fully connected layer to output the Q-values for the six possible actions.
Results
All the result videos can be found in the following YouTube playlist:
https://youtube.com/playlist?list=PLyd5R-snIdOv5p9GStKQkrjmlwmka8-Xo&si=ePVuansyVjbfEqf
1. Initial driving status without model training and autopilot
Before we started to train the model, it was important to check if our code works properly. Since we want to train an RL model, we need to randomly make the car agent start driving around. In the first video, we first test our agent without any training. As the video showed, the agent is just purely driving around and trying to maximize its speed as fast as possible. Since there is no goal point for the agent to drive, the agent is just driving recklessly by crashing into obstacles or driving in the wrong lane. It was also not following the traffic lights. This phenomenon caused the learning result to be unsatisfying even after training with a ton of epochs. Since there is no penalty in the reward function on violating the traffic lights and crossing lanes, the agent was just trying to not collide with other obstacles and driving recklessly. This is not what we want to see.
2. Initial driving status with autopilot but without model training
To deal with the problem mentioned in previous section, we introduce an autopilot
feature
provided by the CARLA simulator. The original driving status of introducing the
autopilot feature can be seen in the second video. With no traffic on the
road, the autopilot seems to be able to drive in the town. Although it sometimes
collides with the obstacle on the road or violating the other lanes, it still can be
able to finish its job.
However, when it comes to adding traffic in the town as the
third video showed, with more obstacles in the town, the higher the chance
that the autopilot failed to drive properly. Therefore, we can now train the
model
based on the autopilot feature instead of purely train the model from a random
state.
The fourth video showed the initial training with
autopilot feature in a nontraffic world. (Note that you can consider “autopilot”
feature somehow act as a “pretrained weight” in model training, although it is
not
actually a machine learning model weight or deep learning model weight.)
3. Halfway model training result with autopilot
After training with 20000 frames, which is half the way of the total training,
the agent can now be way better to drive in the town with traffic. Although it
still sometimes runs into obstacles or other cars, there is a significant
improvement compared to the original autopilot. The fifth video showed
the result of halfway training.
4. Final model training result with autopilot
The final model of the training with 40000 frames is quite satisfying. The agent is now able to drive safely in the town in both situations – with traffic and without traffic. There is no collision that occurs and the agent can drive smoothly without invading the other lanes. The sixth video (left one) showed the agent of final model driving in a nontraffic world while the seventh video (right one) showed the agent of final model driving in a traffic world.
Driving in a nontraffic world
Driving in a traffic world
Summary
Initially, without any training, the agent drove recklessly, aiming only to maximize
speed, resulting in frequent crashes and traffic violations. This approach led to
unsatisfying learning results. To address this, CARLA's built-in autopilot was
introduced as a baseline guide. While the autopilot could navigate an empty town, its
performance degraded significantly with traffic. The model was then trained using the
autopilot as a starting point. After 20,000 training frames, the agent showed
significant improvement, although it still had occasional collisions. The final model,
after 40,000 frames, was quite satisfying, enabling the agent to drive smoothly and
safely in environments both with and without traffic, avoiding collisions and adhering
to lanes.
The trained agent demonstrated a marked improvement over both its untrained state and the baseline CARLA autopilot. It successfully navigated smoothly, avoided collisions, and maintained lane discipline in various scenarios. However, there is room for improvement. The current six-action discrete control could be modified to be linear for smoother driving. Additionally, the reward function could be adjusted to penalize stopping, as the agent sometimes stops indefinitely behind a stalled vehicle to avoid a collision.
Reference
> For full report, please visit: https://drive.google.com/file/d/1D8MMZFLiElux2fCvvzgI47pYHE62upQL/view?usp=sharing
> For project code, please visit: https://github.com/htliang517/CARLA_RL